As data continues its exponential growth across enterprises, organizations are facing significant challenges in harnessing it to power their AI and analytics initiatives. Data is rapidly spreading across on-premises systems, multiple clouds, applications, and geo-locations. This creates data silos, higher governance and security risks, increased complexity, and soaring costs.
According to IDC, by 2025 the global datasphere will grow to 163 zettabytes, with a staggering 80% comprising unstructured data like files, streams, IoT data and more. Traditional data warehouses are too constrained and rigid to handle these diverse data workloads cost-effectively. While data lakes provided more flexibility, they lacked the governance and performance required for enterprise analytics.
Data lakehouses have emerged as a new architectural approach to combine the advantages of data warehouses and data lakes. However, first-generation lakehouses still had key limitations like single query engine support, lack of hybrid/multi-cloud deployments, and minimal governance capabilities.
IBM is tackling these challenges head-on with Watsonx.data – an open, hybrid, and governed data lakehouse optimized for all data workloads and AI use cases.
What is IBM Watsonx.data?
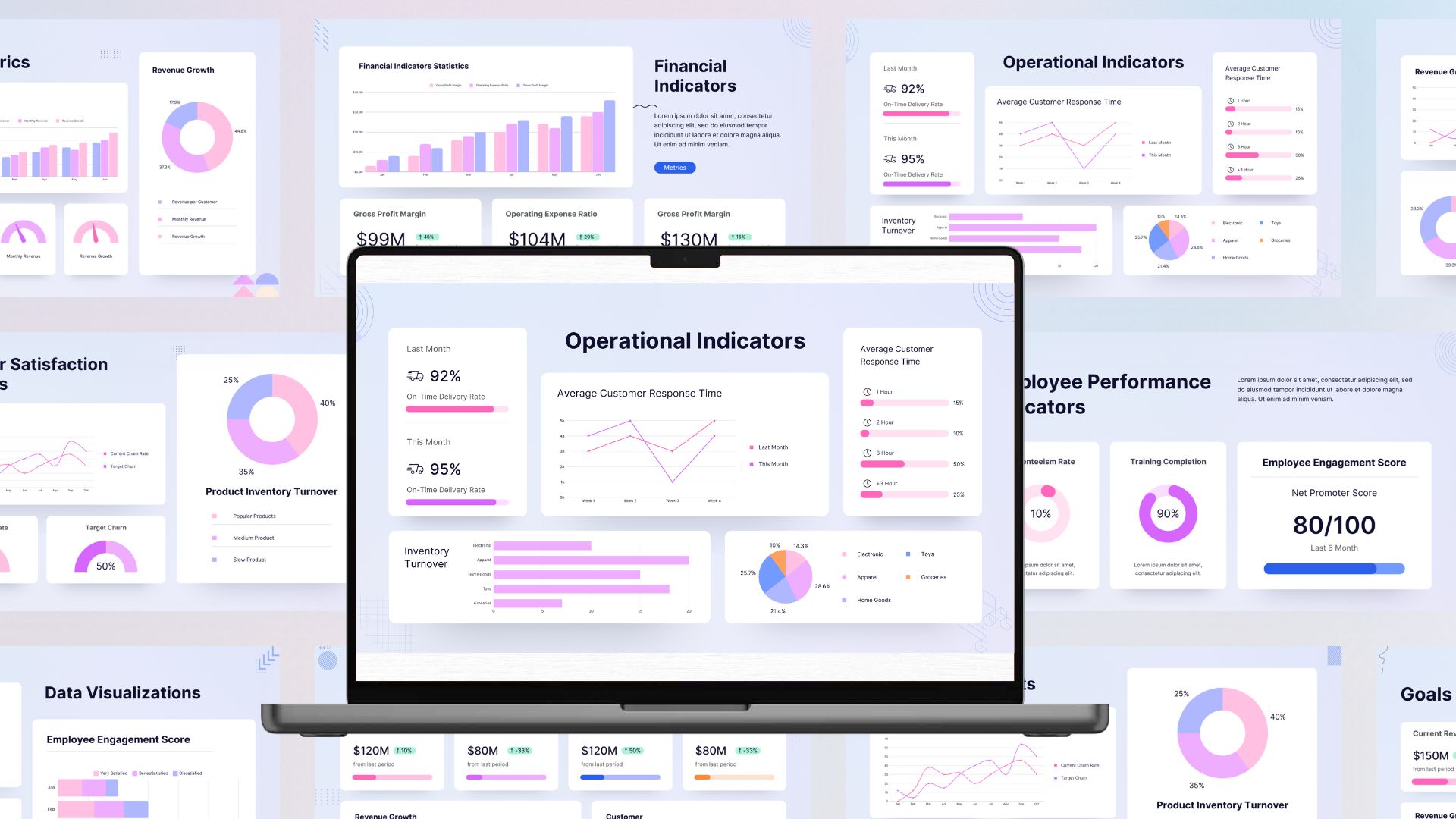
Watsonx.data is IBM’s highly scalable and performant data lakehouse designed to simplify data management across hybrid cloud environments. It provides a single point of entry to access all your data through a shared metadata layer spanning public clouds like IBM Cloud, AWS, Microsoft Azure and on-premises systems.
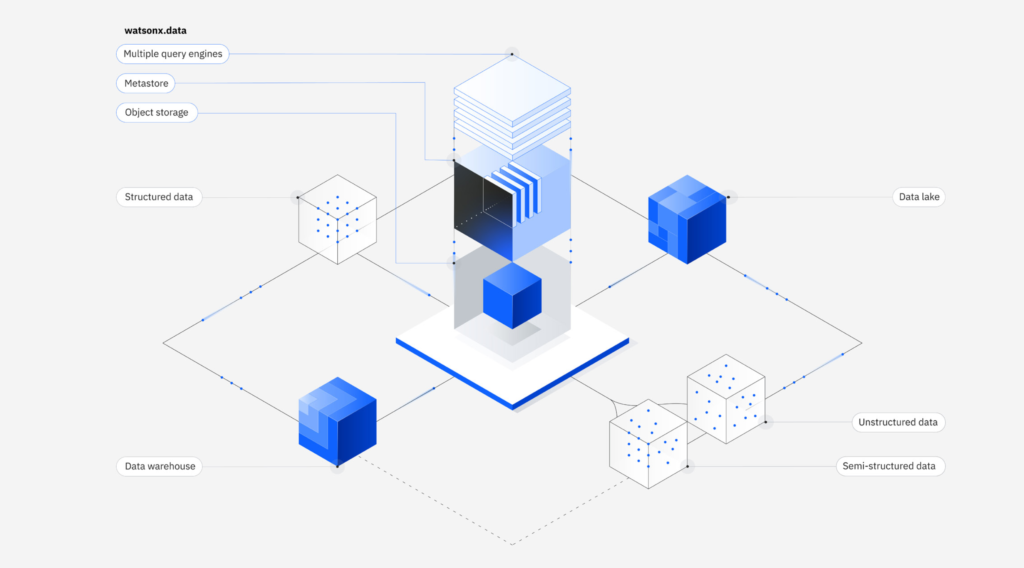
At its core, Watsonx.data features an innovative architecture with multiple query engines, open data formats, built-in data governance and metadata management. This allows you to optimize for cost and performance by using the right engine for the right workload and storage tier.
For example, you can leverage high-performance yet cost-effective engines like Presto for BI/reporting workloads and Spark for machine learning/data science workloads. The platform dynamically scales up or down based on your needs. You can quickly add new engines to meet evolving price-performance requirements.
Watsonx.data is built on open source technologies and open data formats like Apache Iceberg, Parquet, Avro and more. This openness enables collaboration by allowing different engines and data consumers to access and share the same data concurrently, reducing wasteful data duplication.
Key Capabilities
- Hybrid Cloud Data Access: With Watsonx.data, you can connect to all your data stores and analytics environments spanning clouds and data centers with a low-code, no-code experience. Its shared metadata layer provides a single pane to view, manage and access data wherever it resides.
- Optimized for All Data Workloads: By separating compute from storage, Watsonx.data allows you to employ the optimal engine and resource configuration for each workload while minimizing costs. Use low-cost object storage and dynamically provision processing power with fit-for-purpose engines like Presto and Spark.
- Unified Data Governance: Robust data governance and security are built into the core of Watsonx.data. You can enforce enterprise-wide data access policies, data masking rules, row/column-level security and more. It integrates with IBM’s data catalog and governance solutions for centralized metadata management.
- Automation and Ease of Use: With Watsonx.data, you can get started rapidly using pre-integrated AI models for data discovery, preparation, curation and visualization – all through a simple, conversational interface. It connects natively to IBM tools like DataStage for data ingestion, and Databand for data observability.
- Open and Extensible: Watsonx.data embraces open source at its foundation with support for open formats, engines and integration with popular data science/ML tools. Its extensible architecture lets you easily add your choice of engines and connect to third-party data sources and applications.
Need Watsonx.data Training? Enroll for
Key Benefits
- Reduce Data Warehouse Costs by up to 50%: By offloading data warehouse workloads to Watsonx.data, optimizing with fit-for-purpose engines like Presto, and taking advantage of low-cost storage, organizations can reduce costs by up to 50% compared to cloud data warehouses.
- Accelerated Time to AI Value: With built-in AI capabilities for data prep, curation and cataloging, Watsonx.data accelerates the data-to-AI pipeline. Enterprises can get AI initiatives to production faster using their trusted, governed data.
- Simplified Hybrid Cloud Architecture: Watsonx.data eliminates data silos with a unified store across hybrid and multi-cloud landscapes. You can modernize analytics seamlessly, without complex data migrations or rewriting workloads.
- Strengthened Data Trust and Compliance: Robust governance, security, data lineage and observability baked into Watsonx.data promotes data trust, compliance with regulations like GDPR/HIPAA, and responsible AI practices.
Real-World Deployments
Watsonx.data is already being used by enterprises across industries to power large-scale, production analytics and AI workloads:
– A major European ride-sharing and mobility company runs over 30,000 queries per day on a 300PB data lake for 1000+ users
– A leading digital advertising platform handles over 2 million queries daily across 7000 users and 50PB of data
– A top internet technology firm processes 1 million queries per month scanning 40PB of data for over 2700 users
– Usage scenarios span business intelligence, reporting, data science, fraud detection, predictive analytics, and more
Want to Buy Watsonx.data? Visit
Getting Started
We provide flexible options to get started with Watsonx.data:
- Free Trial: Try out the core capabilities of Watsonx.data through a free trial environment by signing up for a free trial here
- Partnership: Leverage Cresco’s expertise in Watsonx.data. We can provide guidance, education, and support throughout your AI journey across your organization.
Cresco has deep enterprise data management expertise from its market-leading database and AI solutions. With Watsonx.data, we are combining the best of open source innovation and its proven software capabilities into a powerful, yet open data lakehouse.
If your organization is looking to harness growing data complexity to cost-effectively scale AI initiatives while strengthening data governance, IBM Watsonx.data could be the solution you need.